Это адаптация фрагмента материала «The Great A.I. Awakening» (Gideon Lewis-Kraus, The New York Times Magazine, 14.12.2016). Оригинальный текст https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html. Адаптация подготовлена при поддержке бюро переводов из Москвы.
Лингвистический поворот
К 2014 году подразделение Google Brain прошло путь от небольшой группы из нескольких человек до быстро растущей лаборатории. Первые победы — нейросети, распознающие речь и изображения, — открыли дорогу к следующему вызову: научить машину работать со структурой языка. Это означало одновременно две стройки: новую техническую инфраструктуру под нейронные вычисления и новую теоретическую базу для языковых задач.
Нынешние сто с небольшим членов Brain — часто это пространство ощущается не столько отделом внутри гигантской корпоративной иерархии, сколько клубом, научным обществом или межгалактической кантной — за прошедшие годы стали одними из самых свободных и широко почитаемых сотрудников во всей организации Google. Сейчас они размещаются в двухэтажном здании цвета яичной скорлупы, с большими окнами, тонированными в угрожающий тёмно-серый цвет, на покрытой листвой северо-западной окраине главного кампуса Google в Маунтин-Вью. В их микрокухне есть стол для кикер-футбола, которым я ни разу не видел, чтобы пользовались; установка Rock Band, которую я тоже никогда не видел в деле; и набор для игры в го, который я видел в деле пару раз. Однажды я действительно видел, как молодой научный сотрудник Brain знакомил коллег со спелым джекфрутом, разделывая огромный шипастый шар, словно индейку.
Когда я начал бывать в офисах Brain в июне, там стояли ряды пустых столов, но на большинстве из них уже были стикеры с надписями вроде «Джесси, 27/06». Теперь все эти столы заняты. В мой первый визит с парковкой не было проблем. Ближайшие места были зарезервированы для будущих мам или для Tesla, но на остальной парковке было полно места. К октябрю, если я приезжал позже 9:30, мне приходилось искать место через дорогу.
Проблема масштаба

Рост Brain вызывал у Дина некоторое беспокойство о том, как компания справится с таким спросом. Он хотел избежать того, что в Google называют «катастрофой успеха» — ситуации, когда теоретические возможности компании начинают опережать её практическую способность внедрить продукт. В какой-то момент он сделал приблизительные расчёты «на салфетке» и представил их руководству однажды в виде презентации из двух слайдов.
«Если в будущем каждый будет разговаривать со своим Android-телефоном по три минуты в день, — сказал он им, — вот сколько машин нам потребуется». Им нужно будет удвоить или утроить свои глобальные вычислительные мощности.
«Это, — заметил он, сделав небольшую театральную паузу и широко раскрыв глаза, — звучит страшновато. Пришлось бы» — он замялся, представляя последствия — «строить новые здания».
TPU: специальное железо для нейросетей

Однако был и другой вариант: просто спроектировать, запустить в массовое производство и установить в распределённых дата-центрах новый тип микросхем, чтобы ускорить всё. Эти микросхемы назвали TPU (tensor processing units — тензорные процессоры), и их ценностное предложение — как ни парадоксально — состоит в том, что они намеренно менее точны, чем обычные чипы.
Вместо того чтобы вычислять 12,246 × 54,392, они выдадут вам приблизительный ответ на 12 × 54. На математическом уровне, а не метафорическом, нейросеть — это просто структурированная последовательность из сотен, тысяч или десятков тысяч перемножений матриц, и гораздо важнее, чтобы эти процессы были быстрыми, чем точными. «Обычно, — сказал Дин, — специализированное железо — это плохая идея. Оно обычно ускоряет что-то одно. Но из-за универсальности нейросетей вы можете использовать это специализированное железо для множества других вещей».
Векторные представления слов
Как раз когда процесс проектирования микросхем подходил к концу, Ле и двое его коллег наконец продемонстрировали, что нейросети можно настроить на обработку структуры языка. Он использовал идею, известную как «векторные представления слов» (word embeddings), существовавшую уже более десяти лет. Когда вы обобщаете изображения, вы можете «увидеть» картинку на каждом этапе обобщения — край, круг и т.д. Когда вы подобным образом обобщаете язык, вы, по сути, создаёте многомерные карты расстояний между одним словом и любым другим словом в языке, основанные на их типичном употреблении.
Машина не «анализирует» данные так, как это делаем мы — с помощью лингвистических правил, определяющих одни из них как существительные, а другие как глаголы. Вместо этого она сдвигает, скручивает и искажает слова на карте. В двух измерениях такую карту не сделать полезной. Вам, например, хочется, чтобы «кошка» находилась примерно рядом с «собакой», но также хочется, чтобы «кошка» была рядом с «хвост», рядом с «надменный» и рядом с «мем», потому что вы пытаетесь уловить все возможные отношения — и сильные, и слабые — которые связывают слово «кошка» с другими словами.
Оно может быть связано со всеми этими словами одновременно, только если каждое из этих отношений представлено в отдельном измерении. Нельзя просто так взять и создать 160-тысячемерную карту, но, как выяснилось, язык вполне неплохо можно представить всего лишь в тысяче или около того измерений — иными словами, во вселенной, где каждое слово обозначено списком из тысячи чисел. Ле мягко подшучивал надо мной за мои постоянные просьбы дать мысленную картинку этих карт. «Гидеон, — говорил он с тем же туповатым упорством, что и bartleby¹ — „Я вообще не люблю пытаться визуализировать тысячемерные векторы в трёхмерном пространстве“».
Перенос смысла через языки
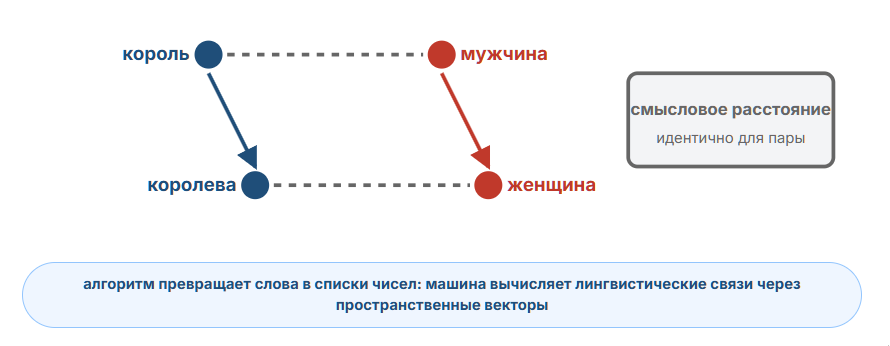
И всё же, как оказалось, некоторые измерения в этом пространстве действительно соответствуют понятным человеческим категориям, таким как род или относительный размер. Если вы возьмёте тысячу чисел, означающих «король», и буквально вычтете из них тысячу чисел, означающих «королева», то получите тот же числовой результат, что и при вычитании чисел для «женщины» из чисел для «мужчины». И если взять всё пространство английского языка и всё пространство французского, то можно — по крайней мере, теоретически — обучить сеть тому, как взять предложение в одном пространстве и предложить его эквивалент в другом.
Нужно просто скормить ей миллионы и миллионы английских предложений на входе и соответствующие им желаемые французские варианты на выходе, и со временем она распознает релевантные паттерны в словах так же, как классификатор изображений распознает паттерны в пикселях. Затем вы сможете дать ей предложение на английском и попросить предсказать лучший французский аналог.
Последовательность во времени и новые горизонты
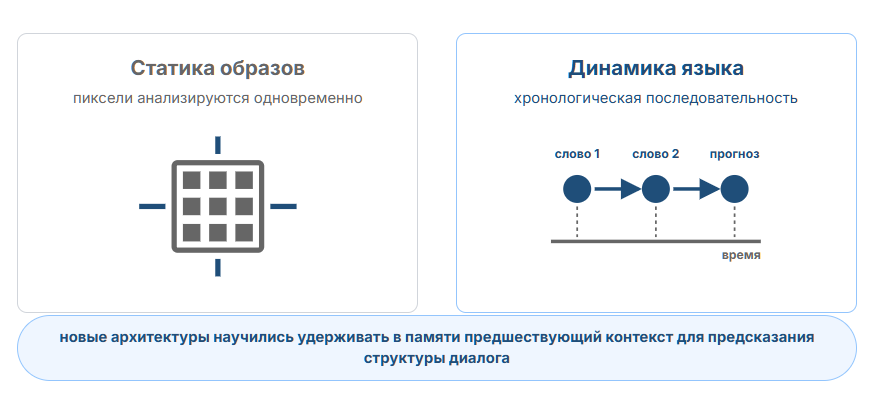
Однако главное различие между словами и пикселями заключается в том, что все пиксели в изображении присутствуют одновременно, тогда как слова появляются в последовательности, развёрнутой во времени. Нужен был способ, позволяющий сети «удерживать в уме» развёртывание временно́й последовательности — полный путь от первого слова к последнему.
За примерно одну неделю в сентябре 2014 года вышли три статьи — одна Ле и две других, написанные учёными из Канады и Германии, — которые наконец-то предоставили все необходимые теоретические инструменты для подобных задач. Эти исследования открыли путь к амбициозным проектам, таким как Brain'овский Magenta — исследование того, как машины могут генерировать искусство и музыку. Они также расчистили путь для прикладных задач, таких как машинный перевод. Хинтон сказал мне, что тогда он думал, что эта последующая работа займёт по крайней мере ещё пять лет.
¹ bartleby — отсылка к персонажу Германа Мелвилла, конторщику Бартлби, чья фраза «I would prefer not to» («Я предпочел бы не делать этого») стала символом пассивного сопротивления.